Step One: Functional Requirements Development
A Dublin Core Application Profile (DCAP) outlines the process for defining metadata records in the context of RDF that meet specific application needs while providing semantic interoperability with other applications on the basis of globally defined vocabularies and models such as Schema.org, Dublin Core element set and terms, IEEE LOM, ISO Metadata for Learning Resources (MLR), and the Achievement Standards Network (ASN) to name but a few. A DCAP promotes the sharing and linking of data within and between communities. The resulting metadata integrates with a Semantic Web of Linked Data and provides the structure relied on by today's Web search engines.

The initial requirement of a DCAP is the articulation of what is intended and can be expected from data. Functional requirements guide the development of the application profile by providing goals and boundaries and are an essential component of a successful development process. Use cases and scenarios frequently help elicit functional requirements that might otherwise be overlooked. The use cases and functional requirements of a Credential Transparency Application Profile (CT-AP) will form the basis of evaluating the CT-AP being developed for internal consistency and for giving guidance on the appropriateness of the application profile for the defined uses.
Focus Areas
The Credential Engine Project has a three-fold focus impacting Step 1:
- development of a Semantic Web-based metadata infrastructure for describing the entities of interest in the credential ecosystem;
- development of an open Credential Registry to manage and provide access to the descriptions created; and
- development of a set of four applications to provide support for learners, employers, job seekers and other stakeholders accessing the Credential registry:
- Credential Directory (CD) Application
- Employer Signaling and Talent Pipeline Management Application (ES)
- Credential Transfer Value Application (CTV)
- Competency Authoring Application (CA)
The Credential Engine Technical Advisory Group (TAG) will review, refine and expand the functional requirements and use cases for the four major applications, and work with the Credential Engine Technical Team to develop more detailed and tailored requirements and use cases for specific properties including the competencies. For example, one major use case for the Directory Application is finding and comparing information about credentials to make career and education decisions by a student and job-seeker.
The mechanisms for development of the use cases and functional requirements that will drive subsequent stages of development are two-fold: (1) already identified functional requirements and use cases for competency data based on the four applications the Credential Engine will be developing in this and subsequent project cycles; and (2) through open solicitation for input of use cases and functional requirements from stakeholders in the current credential ecosystem.
Use and Functionality
General analysis of existing needs in the credential ecosystem by the Credential Engine project include the following seven broad areas of use and functionality that support the functions of the four applications to be developed and improve the transparency of the competency ecosystem and the capacity of all stakeholders to fully understand the meaning of the competency requirements:
- Search and Discovery - Search for and find credentials with similar competencies within a particular scope of application (e.g., similar degree level, occupational cluster).
- Equivalence - Determine the equivalence between competency requirements among credentials or some other comparison source (e.g., job profile, learning resource, competency framework, quality assurance requirement, military training record, work history portfolio).
- Gap Analysis - Determine the gap between two different competency requirements such as an employer competency requirement and the credential requirement or the credential holder portfolio of one or more credentials.
- Translation/Map - Translate equivalent or similar competency requirements written in one language (e.g., format, types of information, grammar, vocabulary) into another language.
- Connection - Identify education and career paths or progressions between: (a) credentials and the degree of transfer value; (b) potential to stack and build on other credentials; and (c) how to progress in learning sequences (e.g. learning maps).
- Accessibility - Improve the ability of competency requirements to be assessed through assessment approaches that are widely accepted by major stakeholders in the credentialing marketplace.
- Data Analytics - Analyze and measure the degree of transparency, portability, and value in the credentialing marketplace and provide useful paradata on the access and use of the credential data and the original and derived claims of credential registry users.
The Credential Engine Competency Subcommittee will start with a set of functional requirements and use cases for competency data based on the four applications already identified. All four applications require the use of competency data by major stakeholders including employers, job-seekers/students, credentialing organizations, assessment and learning resource providers, quality assurance organizations, and government agencies.
Step Two: Domain Model Development
The Domain Model developed here in Step 2 is an entity-relationship graphic that illustrates the entities to be described using the Credential Transparent Description Language (CT-DL) and the relationships between those entities.

The entities and relationships of the Model will be developed by the Credential Engine Technical Advisory Group working with the Credential Engine Technical Team through analysis of:
- the use cases and functional requirements;
- the project design goals;
- information gathered and synthesized by the Credential Engine project of the work product of recognized entities in the competency ecosystem including their credentials, competencies, workforce models (including job and employee competency models), and resource description languages;
- Credential Engine project assessment of the credential ecosystem and the the positioning of the Credential Engine project within that ecosystem; and
- the project's determined scope of application.
The figure below illustrates the range of entities and their data that will inform the Domain Model development and the resulting CT description language. The Credential Engine Technical Team will provide the Group with synthesized data to support its Domain Model analysis and development.
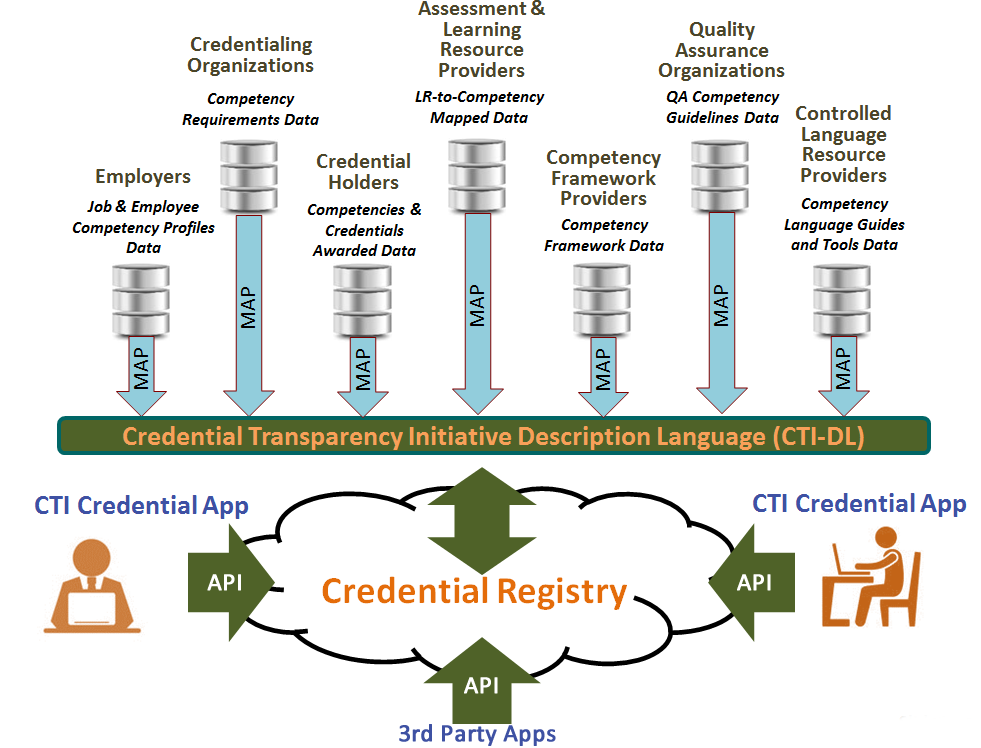
The focus of the Domain Model is on description of Credentials, Credential Issuers, Quality Assurance Organizations and other entities necessary to express the range of credential description data and key relationships. Description of Credential Holders "earning" credentials and Credential Consumers "requesting" verification of credentials are out of the Credential Engine project's scope. The following figure illustrates this intended focus of project scope and the Domain Model.
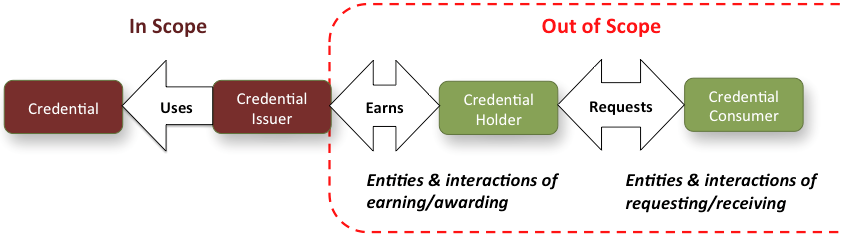
Domain Model in Development Process Context
The design goal for the CI-DL to serve as the credential extension for schema.org, which provides a community domain standard on which the Credential Engine Technical Advisory Group will rely in developing the Domain Model. In the figure below of the DCAP process, the top section 'A' (read left to right) illustrates the application profile development process as outlined in the Credential Engine Technical Planning Approach. As the figure demonstrates, reliance of the Domain Model in 'A' on Domain Standards in 'B'-such as Schema.org-enhances semantic interoperability. Similarly, the Domain Standards in 'B' rely on the W3C's RDF and RDFS foundational standards.
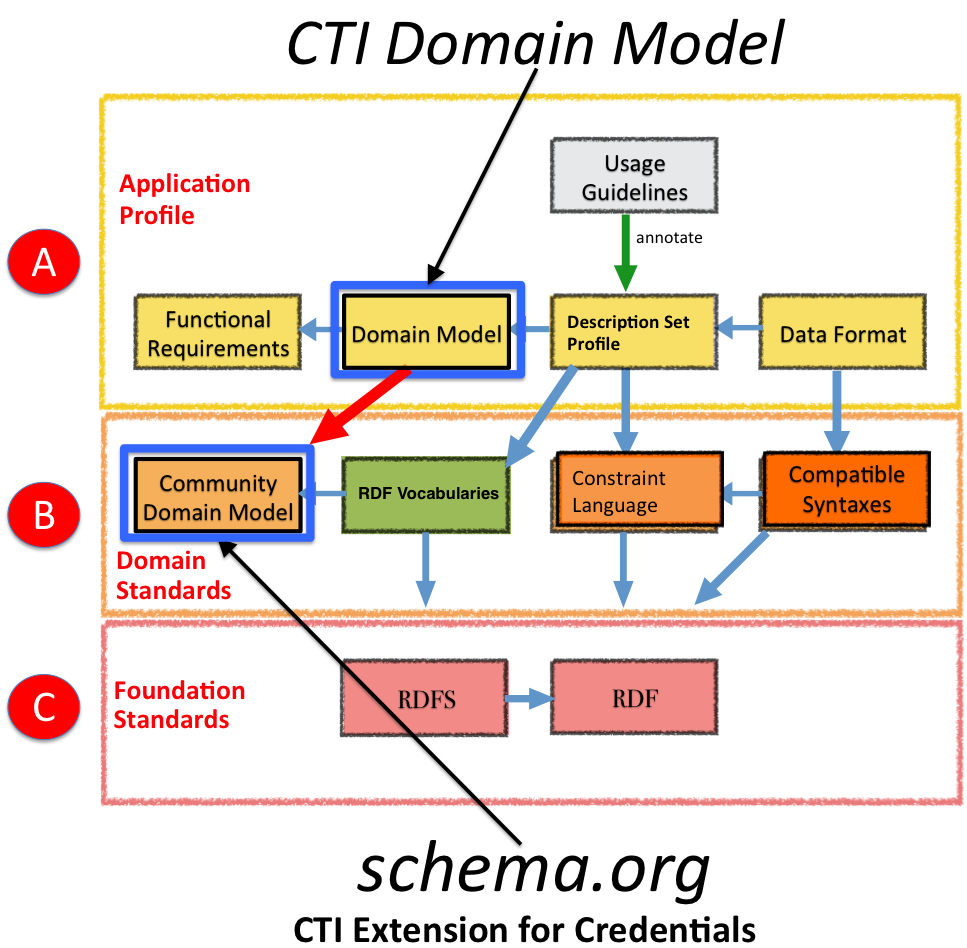
To illustrate this reliance of the CT Domain Model on Schema.org as Community Domain Model, the following preliminary CT entities are suggested:
- Credential as schema.org/CreativeWork;
- Organizations and People as schema.org/Organization and schema.org/Person; and
- Relationships alignment between Credential and related frameworks as schema.org/AlignmentObject;
- as well as others to be determined by the Credential Engine Technical Advisory Group and the Credential Engine Technical Team as their work advances.
General Purpose of the Description Language Developed
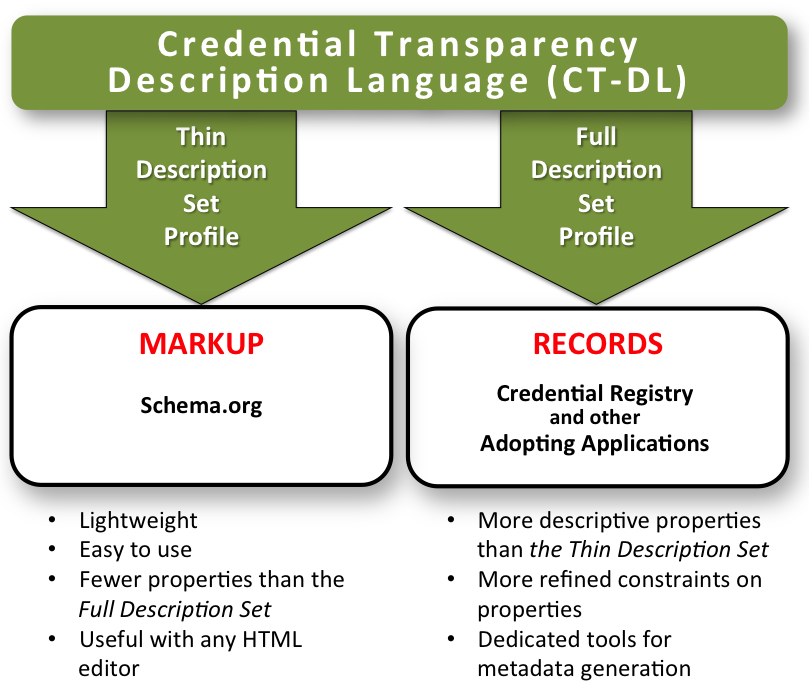
An additional factor affecting Domain Model development is the intended creation of two description sets or graph models: (1) a "full" Domain Model developed for use in rich description of model entities as record structure; and (2) a subset of the full Model intended for easy use in credential data markup for discovery on the Web. The following figure illustrates this dual role of the work:
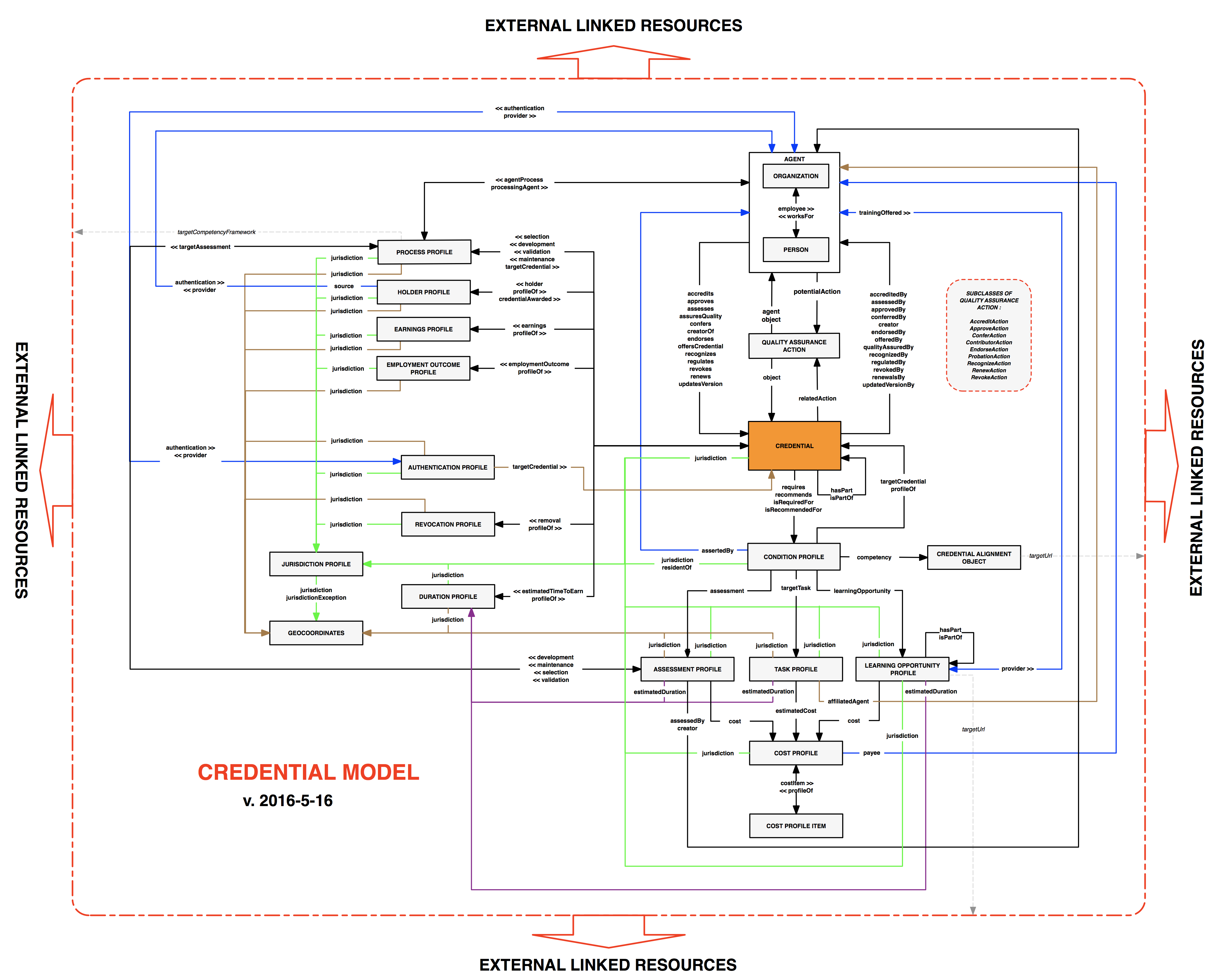
Draft Competency Domain Model
The original draft of the competency/competency framework domain model is below:
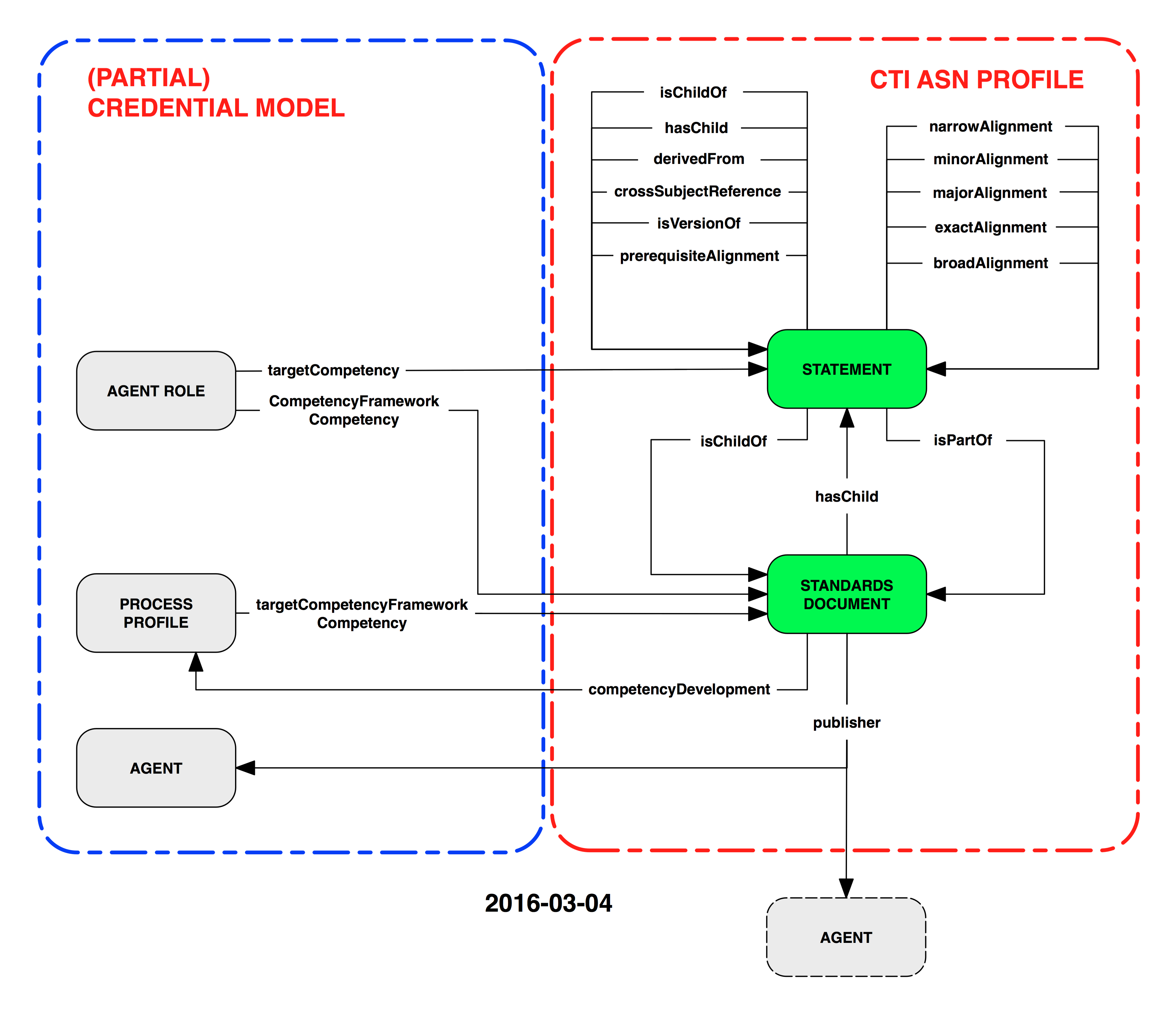
Step Three: Description Set Development
Steps 3 and 4a in the DCAP process are closely related. Step 3 carefully and fully documents in human-readable form the intended Description Set (or general graph shape) of the set of related entities in the Domain Model. For example, a "description set" for a specific credential might, at a minimum, include resource descriptions for:
- the credential,
- an array of resource descriptions of organizations playing roles in the lifecycle of the credential, and
- an array of individual resource descriptions of the competencies addressed by the credential.

Thus, at the close of Step 3, the Credential Engine Technical Advisory Group and the Credential Engine Technical Team will have created human-readable documentation for all classes and properties of which the CT description language (CT-DL) is comprised. In addition, an RDF schema is created using W3C's Resource Description Framework Schema (RDFS) for all properties and classes not borrowed from other namespaces such as schema.org.
In addition, all descriptive datatype properties derived from the use cases and Credential Engine Technical Advisory Group analysis are fully described. These class/property descriptions are also represented in table form following a well prescribed set of property/class attributes.
In Step 4a, the human-readable tables describing the classes and properties of the "description set" are transformed into one or more description set profiles by: (1) recasting the constrained Description Set into a machine-readable form using a Constraint Language; and (2) applying constraints on properties and classes to meet particular needs-e.g., the need for "full" and "thin" applications seen in Figure 4 of Step 2.
Selecting and Creating "Terms"-Properties & Classes
During Steps 1-2, preliminary determinations are made regarding: (a) the types of entities that must be described to support the CT use cases; and (b) the kinds of statements that the metadata must make about each of those entities. Here in Step 3, the Credential Engine Technical Advisory Group and the Credential Engine Technical Team determine whether the entities and the statements called for in the use cases and Credential Engine domain model already exist in publicly available RDF schemas. To support interoperability and broad adoption, the Group should advise the reuse of publicly existing, and well recognized, classes and properties as opposed to unnecessary 'coining' of new terms. The Group's initial focus should be the suitability of Schema.org resource types and their accompanying properties with the goal of the CT-DL being chiefly comprised of Schema.org extensions.
Documenting Table and Properties
Each resource class and each of their associated properties are documented in the Description Set with an individual table describing their attributes. The following table contains rows defining each attribute to be described.
| Attribute | Type | Description |
|---|---|---|
| URI | Class/Property | The Uniform Resource Identifier used to uniquely name/identify the term. |
| Label | Class/Property | The human-readable label assigned to the term. |
| Definition | Class/Property | A statement that represents the concept and essential nature of the term. |
| Comment | Class/Property | Additional information about the term or its application. |
| Type of Term | Class/Property | The type of term-Class or Property-identified by RDF/RDFS URI. |
| Range Includes | Property | The URI(s) of the Class(es) that are either inferred to be used (has range) or that are typically used (range includes) as objects of the property. |
| Domain Includes | Property | The URI of the Class that is either inferred to be used (has domain) or that is typically used (domain includes) as subject of the property. |
| Subproperty Of | Property | The URI of a Property of which the described term is a Subproperty. |
| Subclass Of | Class | The URI of a Class of which the described term is a Subclass. |
At the conclusion of this part of the Step 3, each property and each resource type or class will have been explicitly defined in human-readable form.
For properties and classes in the tables that are coined by Credential Engine, the RDF schema defining those properties and classes has been be created using constructs from W3C's RDF Schema 1.1 data-modeling vocabulary for RDF data.
Step Four A: Description Set Profile(s) Development
Step 3 defined the set of properties and classes to be documented in the Credential Engine application profile as embodied in the resulting Description Set. Here in Step 4, the Description Set Profile (DSP) defines the machine-enforceable constraints on those properties and classes including cardinality, optionality, and precise constraints on the choices and forms of values to be assigned to properties. At a minimum, the outcome of Step 4a is a machine-encoded expression of the Description Set using a formal constraint language required to meet the "record-defining" needs of specific applications such as the Credential Engine Apps.

At best, the constraint language can be used to machine validate a graph in a manner akin to validation of aspects of XML data using an XML schema. While the high-level constraint languages cannot be used directly for validation, they nevertheless provide a precise means for expressing the data through other data models-e.g. XML, JSON, in RDBMS, etc.
Currently, there are two publicly available, high-level constraint languages for describing constraints on an RDF graph and one language for validation under review for standardization by W3C:
- High-level machine description
- Description Set Profiles: A constraint language for Dublin Core Application Profiles (http://dublincore.org/documents/dc-dsp/)
- Library of Congress Bibframe Application Profiles (http://www.loc.gov/bibframe/docs/bibframe-profiles.html)
- Machine validation
- W3C Shapes Constraint Language (SHACL): Working Draft (http://www.w3.org/TR/shacl/)
The Credential Engine Technical Advisory Group will advise and assist the Credential Engine Technical Team in development of an appropriate DSP encoding.
Step Four B: Usage Guidelines Development
The next step is to produce usage guidelines. A Description Set Profile defines the "what" of the application profile. Usage guidelines provide the "how" and "why". Usage guidelines offer instructions to those who will create the metadata records. For Credential Engine, these usage guidelines will explain each descriptor and provide guidance on major decisions that must be made in creating a metadata record.

Step Five: Syntax Guidelines Development
Being based in Resource Description Framework (RDF) and the Project Design & Process Objectives, the outcomes of Steps 1 through 4 are syntax neutral-i.e., no final decisions are made as to how the data will be serialized. This stands in sharp contrast to development processes that assume a format or syntax (e.g., XML) up front and model the data to meet the peculiarities of the chosen syntax. Thus, the graph modeling for RDF and Linked Data and the DCMI DCAP do not require any particular machine-readable encoding syntax as long as the syntax employed can fully express the values and relationships defined in an application profile. Following these guidelines, the Credential Engine Technical Advisory Group and the Credential Engine Technical Team will develop various encoding guidelines for Credential Engine metadata in RDFa and Microdata for HTML/XHTML tagging of web pages, RDF/XML, JSON-LD, and Turtle, with others added in the future from the growing array of graph bindings.


