Traversing Data Landscapes: CTDL Schema Crosswalks
Introduction
The data landscape includes interconnected data ecosystems which are networks of data sources, platforms, tools, and processes that collectively enable the collection, storage, management, analysis, and sharing of data. Broadly, education and employment are ecosystems that tend to be fragmented and siloed. Within these broad ecosystems are many niches in which data sharing is a necessity to empower individuals to find the best pathways.
Integral to the CTDL development process is identifying existing schemas that are relevant to the depth and breadth of the CTDL and mapping them. Further, crosswalking CTDL to other schemas or standards provides useful information for integrations and for eventual harmonizing of standards. Credential Engine's CTDL team began using the Data Ecosystem Schema Mapper (DESM) with a Chartered Rubrics Task Group that included crosswalking rubric standards as in scope. Going forward, the CTDL team plans to continue to scope in use of the DESM tool to replace past practice of using spreadsheets for crosswalks.
Doing a mapping and developing a subsequent crosswalk provides CTDL with the means to:
- Avoid unnecessary proliferation of content standards through clear knowledge of relevant existing public data models for potential reuse;
- Make mappings among the relevant data models clear and transparent;
- Determine the level of expressivity of each data model in comparison to the other models thus helping identify common and less common attributes;
- Help determine whether new CTDL terms should or should not use terms in
- existing data model namespaces;
- Provide information needed to determine whether any CTDL terms (existing or new) should technically specify relationship alignments to terms in other existing data models in conformity to the CTDL Namespace Policy to support data interoperability;
- Support the aggregation, repurposing, and transforming of rubric metadata expressed using different data models; and
- Add new CTDL terms to the mapping; and, thereby, fill gaps to support our existing and aspirational use cases.
This document is intended to introduce DESM, its functionality, examples of use cases supported, and other related topics to help utilize the tool for CTDL crosswalks to other standards. It will be updated over time as additional mapping guidance is developed.
Mapping/Crosswalks 101
For our purposes, "'mapping' refers to the intellectual activity of [comparatively] analyzing two or more metadata schemas; 'crosswalks' are the visual and textual product of the mapping process."
Types of Mapping:
- Intellectual Mapping
- Comparing the attribute definitions and extensions of the mapped schemas
- Comparing value space definitions and textual formulation of data values (e.g.dissimilar treatment of personal names - "Smith, Jack" or "Jack Smith")
- Technical Mapping (syntactic / structural interoperability)
- One-to-many and many-to-one (e.g. "name=Jack Smith" to/from "firstName=Jack" / "lastName=Smith")
DESM Tool Overview
The DESM Tool is software (https://tool.desmsolutions.org/) that was developed through a T3 Innovation Network project. Data standards are frequently mapped together to determine how they are similar and dissimilar in content and coverage and to allow the "crosswalking" of data from one standard to another. It is appropriate to utilize DESM for mappings that involve two or more schemas that overlap with their intended use.
The DESM tool currently focuses primarily on intellectual mapping with some limited attention to noting technical mapping issues.
- The DESM Tool is software designed to support and sustain schema mapping projects based on the definitions for properties and controlled vocabularies.
- Mappings are agnostic to data formats and serializations.
- Mappings can be between an arbitrary number of data standards through the automatic generation of an artificial or "synthetic" spine to which each standard is mapped.
- The software is available via GitHub under an Apache 2.0 open license to support setting up instances that could be used to complete schema mappings across any domains.
- DESM supports mappings between an arbitrary number of data standards through the automatic generation of an artificial or "synthetic" spine to which each standard is mapped.
- DESM supports numerous use cases such as mapping schemas for LERs. See the DESM Benefits and Supported Use Case Examples section for more information.
DESM User Roles and Functions
The DESM Tool has the following user roles that require authentication and role management:
- Administrator: This role is for setting up mapping project configurations.
- Mapper: This role is for uploading and mapping schemas. Mappers are associated with an organization and an organization can identify multiple mappers.
- Lead Mapper: The Mapper role includes one or more Lead mappers who have permissions to finalize the status of a mapping.
- Facilitator: A Facilitator role is also recommended. A Facilitator works with mappers to define the mapping project, facilitate mappings, and do quality checks. Facilitators may need to be given access to each Mapper's workspace.
Using the DESM Tool begins with setting up a configuration specific to a mapping project. Prior to setting up the configuration profile, it is essential for all mappers to meet and reach a common understanding of the mapping project. Mappings are created by people, referred to as mappers, with expertise in the schemas being mapped. It could be possible, in the future, for the tool to utilize AI to create the mappings that get validated by people with expertise in the mapped schemas.
Below is a listing of the five essential functions supported by the DESM Tool.
Configuration Profile
DESM mappings begin setting a Configuration Profile to:
- define the abstract classes to be mapped;
- define the predicates used to indicate how close schema definitions match, and
- identify the organizations and their users participating in a mapping project as mappers.
Once a configuration is defined by administrators, a mapping project can commence. One or more mappers for each organization are identified as lead mappers, giving authority to determine if a mapping is complete and share the output. All Mappers must have a solid understanding of the schema they are mapping regardless of their relationship or lack thereof to the schema's creator.
An abstract class is created for the purpose of mapping properties that relate to similar classes from different schemas. Abstract classes are used to create DESM mapping configuration profiles that are unique to each mapping project for the purpose of identifying the classes applicable to that project. However, nothing precludes a mapping project from reusing the abstract classes file developed for a different project. The Mapping Predicates are also defined with the configuration profile that can be standardized across all mapping projects or specific to a mapping project. See the Mapping Predicates section of this document for the terms and definitions used with the DESM Pilot Project.
Uploading Schemas
Mappers upload their schemas formatted in any of the below-listed native formats that are relevant to the abstract classes defined by the Configuration Profile. The supported file formats include:
- JavaScript Object Notation Schema (JSON-Schema) zipped archive file:
- Use a validation tool to check for JSON conformance https://www.jsonschemavalidator.net/
- Make sure that all relevant files are included in the archive so that
$refdependencies can be resolved. - RDF Schema and SKOS serialized as any of the following (Use a validation tool to check for RDF conformance):
- Extensible Markup Language Schema Definition (XML XSD) files.
- Comma Separated Value (CSV) file using a DESM standardized template.
Completing Pairwise Mappings
Multiple mappings can be created simultaneously or each mapping participant can work together to schedule their mapping to occur one after the other. Mappings are based on the definition of the property or the controlled vocabulary being mapped via the synthetic spine and use a predefined set of mapping predicates for indicating the closeness of matches.
The DESM Tool provides a drag-and-drop interface to select properties or controlled vocabularies in a queue and map them to the synthetic spine. The first schema upload automatically creates the spine. Subsequent mappers use drag-and-drop functionality to select properties and controlled vocabularies to complete pair-wise mappings to the synthetic spine. The mapper then uses a drop-down menu to select the appropriate predicate for each property or controlled vocabulary mapped to the spine.
Growing a Synthetic Spine
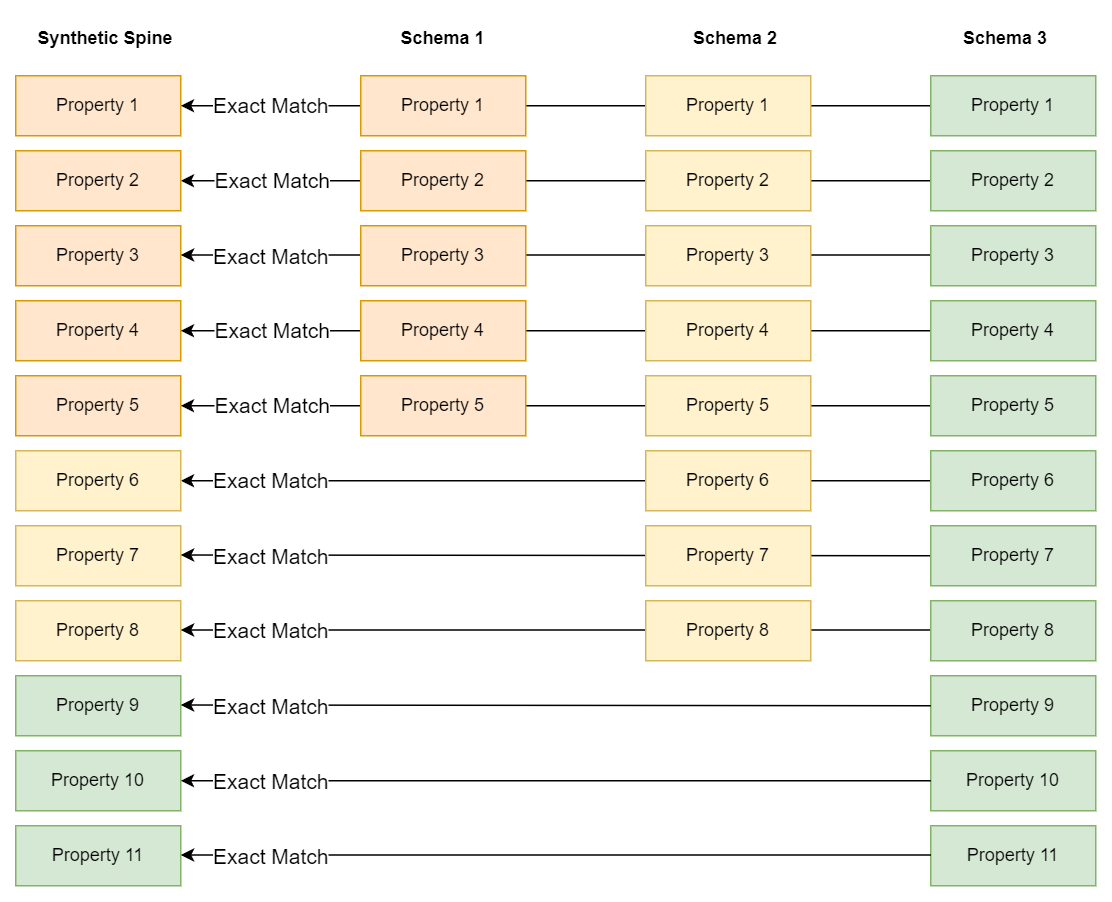
The pair-wise mappings are always to the properties and controlled vocabularies in the synthetic spine. The synthetic spine comprises a schema-neutral set of properties built to encompass all the properties from all of the schemas based on the abstract class being mapped. The synthetic spine grows as mappers identify properties or controlled vocabularies in the schema being mapped that don't have a match. This is an important benefit of using the DESM Tool. This capability ensures every applicable property and controlled vocabulary across the schemas being mapped is available to be included in a mapping project. The figure below depicts three schemas growing a synthetic spine.
Providing Useful Output
The DESM output is currently in two formats:
- A web page for seeing the results of a mapping project that supports information about all of a project's mapped schemas and filtering on the details of the mapping project
- Downloading serialized pairwise mappings as a JSON-LD file useful to developers
DESM Benefits and Use Case Examples
There are numerous benefits that result from creating and sustaining schema mappings ranging from clarifying general confusion surrounding whether or not schemas have any alignment to providing machine actionable data for tools. Further, using a tool that supports uploading valid, native schema formats has the potential for using APIs to ingest updates rather than the past methodology of using spreadsheets or other tools.
The DESM Tool can support numerous use cases, and talent ecosystems across domains. The Tool is agnostic to the type of schemas and domains being mapped.
Some important general use cases that are supported by DESM data include the following use cases identified by the Open Competencies Network's Technical Advisory Workgroup:
- Mappings for Transcoders: As a programmer working on a service consuming data in one or more schemas I want to be able to translate the data from one standard format to another in order to provide data in the schema that best suits the user of that data.
- Informing the T in ETL: Extract Transform and Load is a common step in data migration workflows. As an IT professional involved in data migration I need information on which terms will require transformation and information on what those transformations would be.
- Standards-Neutral Data Model: As a programmer working on a service that deals with (consumes or provides) data in several standard schemas, I want to be able to use a neutral data model and know that data can be transcoded to/from this neutral schema from/to the standards so that I can be confident that my data comply with the necessary standards. This involves aggregating multiple standards into a coherent product or service.
- Gap Analysis: As a representative of an organization creating and maintaining data specifications I wish to identify where my data specifications have gaps so that I can ensure that our data specifications provide full coverage of the domain.
- Data Schema Harmonization: Being involved in data use across a broad range of sectors, I want to be able to use data regardless of where it comes from. DiDifferent sectors will of necessity have different standards, and I can use the best data in systems and data products that span these sectors.
- Academic or Training Use: Use to help learners understand data standards and how they interrelate, as part of a curriculum that includes data standards. The tool can help train people on how to map between standards.
- Data Standars Organization (DSO): Increasingly DSOs are seeing that their standards overlap with standards from other DSOs. One relevant example is how standards for transcripts and learning and employment records overlap with standards for describing credentials and learning opportunities. As a person developing standards with a DSO wanting to facilitate a smoothly operating data ecosystem, I want to map the standard I am working on to other standards in order to see: (i) how users of my standards could obtain data from systems that conform to other standards, (ii) how I could develop my standard so that it directly references other standards.
- Policy and Recommendation Mapping: Organizational and legal policies sometimes require or recommend data properties and/or characteristics of data. Implementation recommendations specify how to use standards and their properties for given use cases. Mapping between one or more existing standards and policies or guidance can reveal where a standard is compliant or compatible. It will be important to indicate where a given property is required vs recommended in the guidance or policy. This use case was not part of the DESM pilot but could be an expansion of DESM.
A couple of real-world examples include the recent development of the IEEE competency data standard. That standard was informed via a baseline mapping of several data standards and Advanced Distributed Learning (ADL) utilized a mapping to inform the Total Learning Architecture (TLA) specification. Currently, there is interest in using the DESM Tool to map credential schemas internationally.
Planning and Scoping Schema Crosswalks
We have found that a lack of shared understanding of the scope and purpose of a mapping leads to poor results.
The recommended steps are:
- Define your project.
- What data models are relevant?
- What do you wish to achieve?
- Form your team.
- You will need experts in each data model and people who understand how the data is used.
- Map the domain in outline.
- What types of entities are important?
- How are they handled in each data model?
- Decide the project details.
- Determine abstract classes, mapping predicates and which model will be first (i.e. will seed the spine)
- Set up a Configuration Profile for a project in DESM.
- Do the mapping in DESM.
- Coordinate the order of the work.
- Have regular check-in meetings to discuss questions.
- Communication is key to consistency between mappers.
- Complete the mapping.
- Check and review the mapping.
- Publish the mapping.
Expect this to be an iterative process, not a one-shot sequence.
Mapping Predicates Example
The predicates listed below resulted from multiple years of developing crosswalks and were tested with the DESM pilot. However, the DESM tool supports configuring mapping projects to use the predicates and their definitions as determined to be relevant to specific projects.
- Identical: The definition is identical in wording and intent.
- Reworded: The definition is identical in intent but reworded; the properties are equivalent.
- Inverse: The spine term and the term being mapped are exact inverses of each other.
- Similar: The definition is similar in intent, but with significant wording differences.
- Transformed: A simple data transform will yield a value for the spine term; for example, concatenating values from several properties being mapped. Describe the transform in a comment on the alignment.
- Sub-property Of: The term in the spine has a narrower definition, covering a subset of the cases where the term being mapped would be used.
- Has sub-property: The term in the spine has a broader definition, covering all of the cases where the term being mapped would be used and more.
- Concept: The definition is related only at a conceptual level, no simple transformation can render the data from one to the other.
- No Match: There is no match for the spine term in the schema being mapped.
DESM Terminology
This list of terms relevant to DESM is not to establish a formal definition, but to ensure communications about the DESM mapping process and outcomes are clear and unambiguous.
- Abstract Class: A class created for the purpose of mapping properties/elements that relate to similar classes/entity types from different schema/standards. Abstract classes are used to create DESM mapping configurations to identify the domains applicable to a mapping project. An abstract class may include within its scope more than one actual class found in DSO schemas; e.g., a "Competency" abstract class may also include a set of adjacent classes such as "Competency Framework" and "Rubric".
- class/entity type: Classes and entity types are groups of things such as persons, places, events, objects, or concepts, that share some defined characteristics. Each class/entity type has associated properties/elements and concepts/controlled vocabularies.
- Concept Scheme/Controlled Vocabulary: Organizes and provides terminology to catalog and retrieve information.
- Data Format and Model Agnostic: DESM mapping is based only on the semantic meaning of individual properties.
- Data Standard Organization: The organization responsible for the management and maintenance of data specifications including schemas.
- Domain: The abstract classes selected to be mapped and the classes selected by mappers that contain the properties and concept schemes to be mapped.
- Mapping Predicate: Defined vocabulary of concepts for the purpose of defining how close or far apart a mapping of one resource is to another resource.
- Pairwise Mapping: A mapping or crosswalk of one resource to another resource for the purpose of determining similarities and differences in content and coverage.
- Property/Element: A unit of data for which the definition, identification, representation, and permissible values are specified by means of a set of attributes.
- Schema: A structure for organizing and defining classes, properties, concept schemes, and concepts.
- Semantic Meaning: The meaning of classes, properties, and concepts based on their definitions.
- Synthetic Spine: The list of properties or concepts each schema is mapped to that can consist of properties or concepts from multiple schemas. This ensures that every property or concept appearing in the mapped schemas has a potential pairwise match.

