Introduction
The Credential Engine project is designing and piloting:
- Credential Transparency Description Language (CTDL)
- an open Credential Registry;
- a Credentials Directory App (search prototype) to be developed during the initial project period with planned development of additional Apps in future project cycles; and
- provision of a Credential Registry API to encourage creation of 3rd party Apps acting on Credential Registry data.
As part of the technical development, Credential Engine has formed a Credential Engine Technical Advisory Group to advise and assist the Credential Engine Technical Team in development of the metadata infrastructure necessary to the creation of the Credential Registry and the project Apps.
Design Goals
In development of the metadata infrastructure for the Credential Engine project, the Credential Engine Technical Advisory Group (TAG) has been charged with the following Design & Process Objectives:
- The metadata infrastructure developed must conform to the W3C (World Wide Web Consortium) specifications for semantic metadata including, but not limited to, Resource Description Framework (RDF), RDF Schema (RDFS), and Simple Knowledge Organization System (SKOS);
- The resulting metadata modeling must be syntax independent and support an array of serializations (e.g., Turtle, JSON-LD, RDFa, RDF/XML, and Microdata);
- The metadata must reuse existing, publicly available properties and classes and not reinvent unnecessarily;
- The metadata modeling must take into account the work of Schema.org, providing the means for the Credential Engine work — or some portion of the work— to serve as the Schema.org extension for Credential description;
- The metadata model must be informed through transparent interactions with partnering and credentialing organizations and feedback from stakeholders; and
- Decisions of the Credential Engine Technical Advisory Group and the Credential Engine Technical Team are made based on rough consensus of Group and Team. Group and Team outcomes are subject to final approval by the Credential Engine Executive Group.
To achieve these objectives, the TAG and the Credential Engine Technical Team (TT) follow the general processes described in the Dublin Core Metadata Initiative's Singapore Framework for Dublin Core Application Profiles (DCAP).
Information and feedback during Group and Team processes are openly shared using a variety of online tools. For example, GitHub is used for metadata/vocabulary, source code, and API. Google Drive and Groups are used for sharing documents and for discussion.
Additional information about the Credential Engine goals can be found on the Credential Engine informational site.
Credential Engine Process Application of DCAP
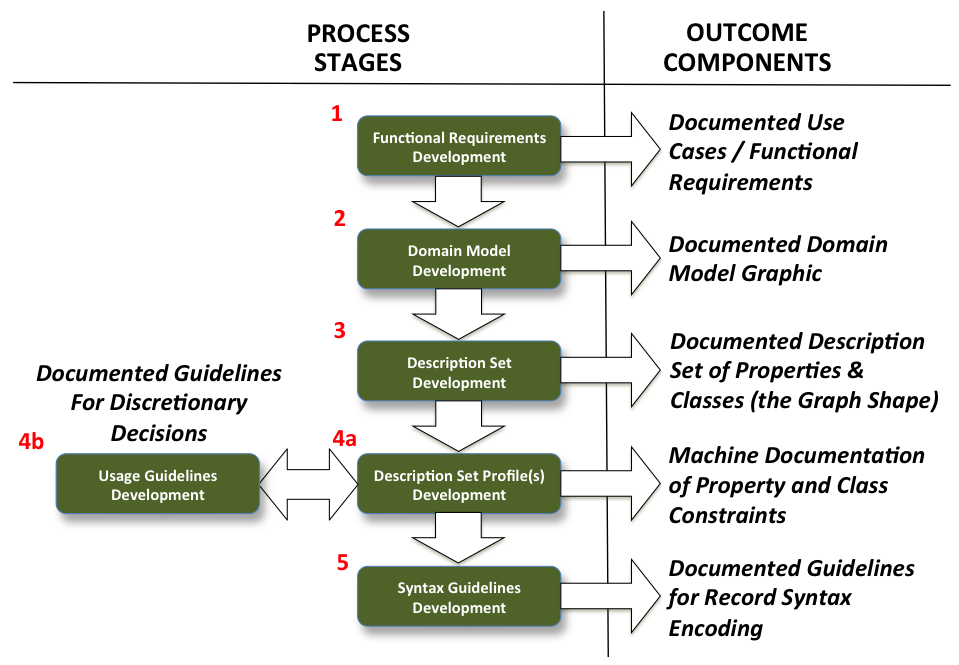
A DCAP is a document (or set of documents) that specifies and describes the metadata used in a particular application. In general, the DCAP process assists in development of the following project assets:
- Functional Requirements - Describes what a community wants to accomplish with its application;
- Domain Models - Graphic characterization or "cartoon" of the types of "things" to be described by the metadata and the relationships between those "things";
- Description Set Profiles - Enumeration of the metadata terms (properties and classes) to be discovered elsewhere or created and subsequently used;
- Usage Guidelines - Human-readable guidelines for usage of the DCAP in generating metadata descriptions; and
- Syntax Guidelines - The machine syntax(es) that will be used to encode the data.
The DCAP process provides the means for applying a series of constraints on the possible things that can be said (asserted) about things in the credentialing environment. As the TAG and the TT work through the development framework illustrated in the DCAP figure below, it will apply five levels of logical, linguistic, and machine-expressed "constrains on the possible."
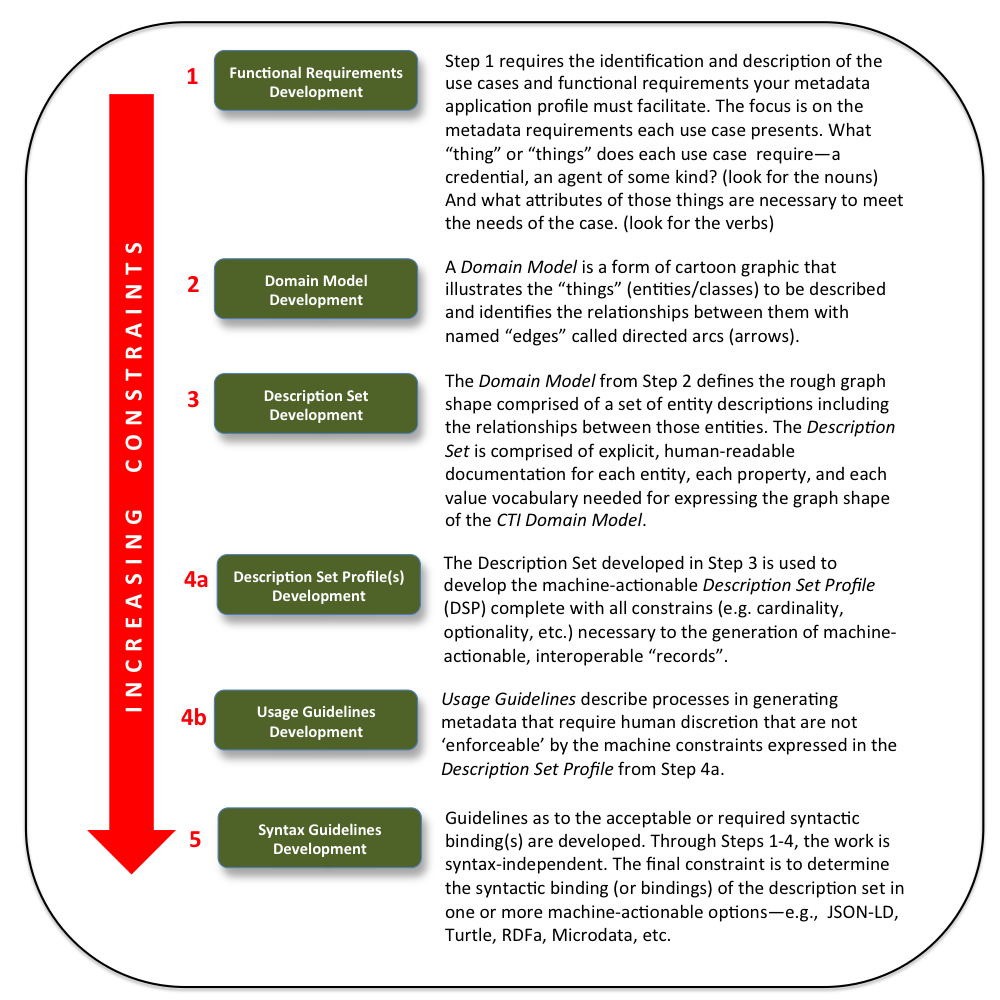
Constraint Level 1
Of all the things in the world of interest to the credential community, which will the Credential Engine Domain Model select, include, and describe? In other words, what classes of things will be chosen and documented to support the generation of metadata that describe real-world instances of the things in the domain? This will be informed by a set of use cases and the Design Goals set out above.
Constraint Level 2
Of all the assertions or statements that can possibly be made about each of those things selected for the Credential Engine Domain Model, which assertions will be included—which will be made possible? In other words, what properties or attributes of the things described will be included in the Credential Engine Domain Model? In this process of constraining, "what can be said" about the things in the model obviously includes an assessment of what will not be said.
Constraint Level 3
Of the assertions or statements selected, what will be the permissible form of expression of each one of them? In other words, is the value of the assertion a literal textual string representing the assertions object or value or is it a non-literal identifying the value?
Constraint Level 4
Of each literal or non-literal value for an assertion, will the permitted values be:
- constrained by requiring that values be picked from one specific controlled vocabulary;
- constrained by requiring that values be picked from a controlled vocabulary belonging to a particular class of vocabularies - e.g., picking a concept from a vocabulary identified as being a member of 'Proficiency Level' vocabularies; or
- constrained by requiring entry of text that is language tagged or datatyped?
Constraint Level 5
Of all the available syntactic bindings suitable for records, which will be supported?
The following figure illustrates these constraints and includes the resulting outcome component or asset.
The levels of constraints are described in greater detail in the following figure and illustrate how each level in the step progression of the DCAP more tightly constrains the content and structure of the resulting metadata.
CTDL Releases
The first release of the Credential Transparency Description Language (CTDL) occurred on November 17, 2016. For more information explore the following:
- CTDL Guide
- Schema Terms
- CTDL Releases (History)
- Schema Serializations
- Namespace Policy
- CTDL Profile of ASN-DL
- CTDL Profile of ASN-DL (How To)
The Credential Registry will publish the resulting schemas, schemes and instance metadata in ways that can be linked to other web-based data using the W3C principles of Linked Data. The Registry will be designed as a neutral data infrastructure enabling the sharing and linking of comparable information on key properties for the full range of credentials.
Credential Engine will also develop and test practical apps (software applications) in cooperation with pilot site partners. These apps will be based on the major functional requirements (what stakeholders need to do with the information) identified for employers, students, educators, and other credential stakeholders. These pilot apps will be developed in ways that will encourage other app developers to participate in an open applications marketplace that can provide additional tools for stakeholders, including government agencies.

